Why do we need indexing a table? Because without an index the SQL server has to scan the entire table to return the requested data. It is like the index page in a book. You check within the index for the keyword you want to learn about. From that point forward, you jump directly to the page where the content belongs, instead of scanning page by page for the material you want to read.
Similarly, a table’s index allows you to locate the data without the need to scan the entire table. You create instead indexes on one or more columns in a table, to aid in the query process.
The following types of indexes are available in SQL Server 2012
- Clustered
- Non-clustered (including covering and filtered indexes)
- XML (primary and secondary)
- Spatial
- Full-text
- Columnstore
Lets focus on the two main index types: Clustered index and Non-Clustered index.
A clustered index alters the way that the rows are physically stored. When you create a clustered index on a column (or a number of columns), the SQL server sorts the table’s rows by that column(s).
Clustered indexes are best when querying:
- a large percentage of columns in the table
- a single row based on the clustered index key
- range-based data
It is like a dictionary, where all words are sorted in an alphabetical order. Note, that only one clustered index can be created per table. It alters the way the table is physically stored, it couldn’t be otherwise.
Syntax:
CREATE CLUSTERED INDEX IX_TestData_TestId ON dbo.TestData (TestId);
ALTER INDEX IX_TestData_TestId ON TestData REBUILD WITH (ONLINE = ON);
DROP INDEX IX_TestData_TestId on TestData WITH (ONLINE = ON);A non-clustered index, on the other hand, does not alter the way the rows are stored in the table. Instead, it creates a completely different object within the table, that contains the column(s) selected for indexing and a pointer back to the table’s rows containing the data.
Syntax:
CREATE INDEX IX_TestData_TestDate ON dbo.TestData (TestDate);
ALTER INDEX IX_TestData_TestDate ON TestData REBUILD WITH (ONLINE = ON);
DROP INDEX IX_TestData_TestDate on TestData;Non-clustered indexes are best when querying:
- only a few rows in a large table
- data that is covered by the index
Note, that SQL server sorts the indexes efficiently by using a B-tree structure. This is a tree data structure that allows SQL Server to keep data sorted, to allow searches, sequential access, insertions and deletions, in a logarithmic amortized time. This methodology minimizes the number of pages accessed, in order to locate the desired index key, therefore resulting in an improved performance.
Relation between clustered and non-clustered indexes
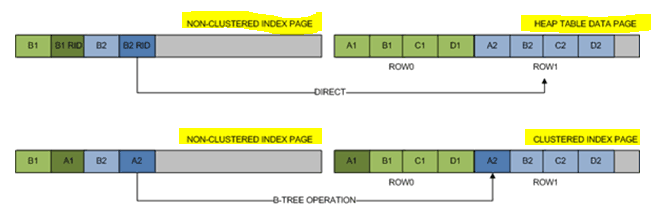
As explained above, a non-clustered index contains a pointer back to the rowID (RID), of the table, in order to relate the index’s column with the rest of the columns in a row.
But this is not always the case:
If a clustered index already exists in the table, the non-clustered index uses the clustered index’s key as the row locator, instead of the rowID reference.
Index: Pros and Cons
A table without a clustered-index is called a “heap table”. A heap table has not its data sorted. The SQL server has to scan the entire table in order to locate the data, in a process called a “scan”.
In the case of a clustered index, the data are sorted on the key values (columns) of the index. The SQL server is now able to locate the data by navigating down from the root node, to the branch and finally to the leaf nodes of the B-tree structure of the index. This process called a “seek”. The later approach is much faster, when you want to filter or sort the data you want to retrieve.
A non-clustered index, on the other hand, is a completely different object in the table. It contains only a subset of the columns. It also contains a row locator looking back to the table’s rows, or to the clustered index’s key.
Because of its smaller size (subset of columns), a non-clustered index can fit more rows in an index page, therefore resulting to an improved I/O performance. Furthermore a non-clustered index can be allocated to a different FileGroup, which can utilize a different physical storage in order to improve performance even more.
The side effects of indexes are related to the cost of INSERT, UPDATE, MERGE and DELETE statements. Such statements can take longer to execute, in the presence of indexes, as it alters the data in the table, thus to the indexes too.
Imagine the situation of an INSERT statement. It has to add new rows in a table with a clustered index. In such case the table rows may need to be re-positioned! Remember…? The clustered index needs to order the data pages themselves! This will cause overhead.
So, it is crucial to take into account the overhead of INSERT, UPDATE and DELETE statements before designing your indexing strategy. Although there is an overhead to the above statements, you have to take into account, that many times, an UPDATE or DELETE statement will execute in a subset of data. This subset can be defined by a WHERE clause, where indexing may outweigh the additional cost of index updates, because the SQL server will have to find the data before updating them.
As explained above, a non-clustered index includes the clustered index’s key as its row locator, in the presence of a clustered index in the table.
This comes with a cost and a benefit:
The cost has to do with the non-clustered index bookmark lookup. What if a query has to return more columns that the ones hosted in the index itself? In the case of a HEAP table, the SQL server would have to check the RID of the non-clustered index, in order to navigate directly to the row, where the rest of the columns belong.
In the case of a clustered index, the SQL server would have to check the row locator of the non-clustered index, in order to do an additional navigation to the B-tree structure of the clustered index, to retrieve the desired row. You see, the row locator does not contain the RID, but the clustered-index key.
On the other hand, there is a benefit. It has to do with the clustered index updates. Imagine the following situation: Two new rows with index key values of A2 and A3 have to be added in the clustered index below.

Because this is a clustered index page, its physical structure has to be reallocated in order to fit A2 and A3 between A1 and A4. It has to maintain index’s order. Since there is no free space in the index page to accommodate these changes, a page split will occur. Now, there is enough space to fit A2 and A3 between A1 and A4.
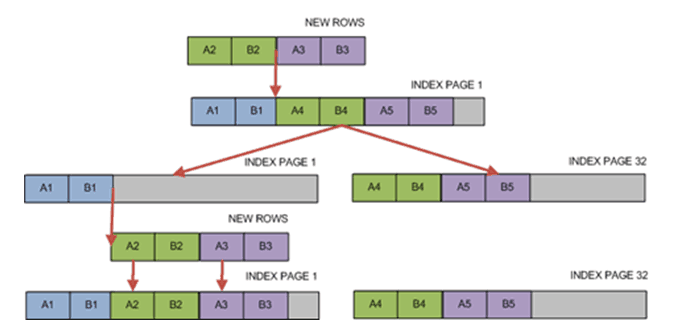
The goal achieved and the order maintained within the index. But imagine what would have happened if the non-clustered index was looking at the RID, instead of the clustered index’s key? It would have to change its row locators to reflect the changes. This could have been a huge performance hit! Especially, in the case of large clustered indexes.
Instead of the RID, the row locators now point at the clustered index key. Meaning, that there is no longer needed to change its values. This is quite a benefit if you think of the large clustered indexes, that are usually maintained in many tables.
Clustered VS non-clustered indexes:
| Clustered Index | Non- Clustered Index |
| This will arrange the rows physically in the memory in sorted order | This will not arrange the rows physically in the memory in sorted order. |
| This will fast in searching for the range of values. | This will be fast in searching for the values that are not in the range. |
| Index for table. | You can create a maximum of 999 non clustered indexes for table. |
| Leaf node of 3 tier of clustered index contains, contains table data. | Leaf nodes of b-tree of non-clustered index contains pointers to get the contains pointers to get that contains two table data, and not the table data directly. |