Azure Data Lake Analytics (U-SQL) originates from the world of Big Data, in which data is processed in a scale-out manner by using multiple nodes. These nodes can access the data in several formats, from flat files to U-SQL tables.
This document focuses on U-SQL tables, with details about table design strategy, different types of partitions that can be created on U-SQL tables and how they differ from each other, the process for incrementally loading data into a partitioned table, and how to manage partitions.
A primary consideration when working with Azure Data Lake Analytics (ADLA) is how the data can be stored. ADLA supports two types of tables (Schema-On-Read and Schema-On-Write) as well as two types of data partitioning (Distributions and Partitions), which enable parallel processing and performance optimizations.
Types of tables
As with other SQL-inspired Big Data processing systems such as Hive, U-SQL provides an option to create either an external table or a managed table that contains schematized structured data. This whitepaper primarily focuses on managed tables, as they provide additional optimizations such as partitioning and distribution, while external tables do not.
When a table is partitioned, the logical table is split into several individually addressable partition buckets (physical files). These partition buckets can further be split into distribution buckets by using a distribution key (Hash/Direct Hash(id)/Range/Round Robin). The purpose of distributions is to group similar data together for faster access.
Syntax
Table_DDL_Statement :=
Create_Table_Statement
| Alter_Table
| Alter_Table_AddDrop_Partition_Statement
| Truncate_Table_Statement
| Drop_Table_Statement.
Partitioning and distributions
Partitioning (a.k.a. Course-Grained or Vertical Partitioning)
Data life cycle management is one reason to use partitions. Creating partitions allows Data Lake Analytics to address a specific partition for processing. Often, data is loaded into Data Lake based on daily or hourly data feeds. These feeds can select a specific partition and Add/Update the data within the partition without having to work with all the data. To accomplish this, each partition must be explicitly added with ALTER TABLE ADD PARTITION and removed with ALTER TABLE DROP PARTITION.
An additional benefit is that the query processor can access each partition in parallel and will perform partition elimination. This greatly benefits the query engine, as partitions that are outside of the predicate where clause are not required to fulfill the result set.
Think of each of these partitions as smaller sub tables with the same schema, which contains rows matching with value in date column, as shown in the following graphic.
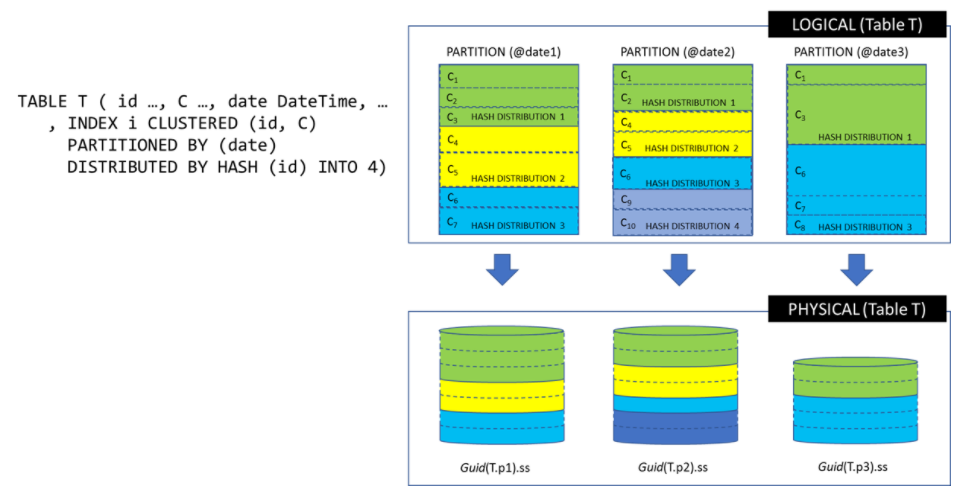
The script below is designed to create a table with vertical partitioning definition on the CalendarYearMonth column.
DROP TABLE IF EXISTS FactInternetSales_Partitioned;
CREATE TABLE FactInternetSales_Partitioned
(
CustomerKey int,
ProductKey int,
OrderDateKey int,
DueDateKey int,
ShipDateKey int,
PromotionKey int,
CurrencyKey int,
SalesTerritoryKey int,
SalesOrderNumber string,
SalesOrderLineNumber int,
RevisionNumber int,
OrderQuantity int,
UnitPrice decimal,
ExtendedAmount decimal,
UnitPriceDiscountPct decimal,
DiscountAmount decimal,
ProductStandardCost decimal,
TotalProductCost decimal,
SalesAmount decimal,
TaxAmt decimal,
Freight decimal,
CarrierTrackingNumber string,
CustomerPONumber string,
OrderDate DateTime,
DueDate DateTime,
ShipDate DateTime,
CalendarYearMonth string,
INDEX IDX_FactInternetSales_Partitioned_CustomerKey CLUSTERED(CustomerKey ASC)
PARTITIONED BY (CalendarYearMonth)
DISTRIBUTED BY HASH(CustomerKey) INTO 25
);
An additional step is needed to create the individual partitions, by using an Alter Table command.
If you wanted to load data by month for 2013, you could create 12 partitions, one partition for each month. You would also create a default partition that is used as a catch all partition. This is considered a best practice when working with partitions in Azure Data Lake (ADL). The below script creates a partition for each month of 2013, along with a default partition. The default/Catch-All partition is used to store records that don’t get placed into any of the other partitions because their values are beyond the current partitions’ boundaries.
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201301"); //Jan, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201302"); //Feb, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201303"); //Mar, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201304"); //Apr, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201305"); //May, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201306"); //Jun, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201307"); //Jul, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201308"); //Aug, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201309"); //Sep, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201310"); //Oct, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201311"); //Nov, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("201312"); //Dec, 2013
ALTER TABLE FactInternetSales_Partitioned ADD PARTITION ("209912"); //Default Partition - Empty
Distributions (a.k.a. Fine-grained Distributions or Horizontal Partitioning)
U-SQL supports distributing a table across each of the partitions created in a managed table. An unpartitioned table will contain a single partition (Default). Distributions further break down a partition into smaller segments. Creating distributions is accomplished by using the Distribution clause in the create statement. Distributions group similar data.
The way a table is partitioned depends on the data and the types of queries being run against the data. Partitions should be used for:
- Design for most frequent/costly queries
- Minimize data movement at query time.
- Mange data skew in partitions.
- Parallel data processing in ADLA.
- Distribution elimination.
Currently, U-SQL supports four distribution schemes: HASH, RANGE, ROUND ROBIN, and DIRECT HASH, as described in the following table
| Distribution scheme | Description |
| HASH | Tables distributed by HASH requires a list of columns (one or more) that will be used to route each row individually to a distribution bucket based on a hash of the columns specified. Like data will always generate the same hash and therefore be located within the same distribution. |
| DIRECT HASH | Uses a single integer column as the distribution bucket. This is often used with ranking functions such as RANK() and DENSE_RANK(). |
| RANGE | This works in way similar to HASH – you provide the key (or ordered keys), and the data will be distributed across the buckets. |
| ROUND ROBIN | This is used when a distribution key can’t be found in the data or when all other distribution options cause data skew within the distributions. This will evenly distribute the data, however, similar data will not be grouped together. This is a good “Catch-All” model to use when none of the other schemes meet your requirements. |
The create a table statement below uses a hash distributed on column “CustomerKey” to slice the data into 25 individual distributions, or distribution buckets.
DROP TABLE IF EXISTS FactInternetSales_NonPartitioned;
CREATE TABLE FactInternetSales_NonPartitioned
(
ProductKey int,
OrderDateKey int,
DueDateKey int,
ShipDateKey int,
CustomerKey int,
PromotionKey int,
CurrencyKey int,
SalesTerritoryKey int,
SalesOrderNumber string,
SalesOrderLineNumber int,
RevisionNumber int,
OrderQuantity int,
UnitPrice decimal,
ExtendedAmount decimal,
UnitPriceDiscountPct decimal,
DiscountAmount decimal,
ProductStandardCost decimal,
TotalProductCost decimal,
SalesAmount decimal,
TaxAmt decimal,
Freight decimal,
CarrierTrackingNumber string,
CustomerPONumber string,
OrderDate DateTime,
DueDate DateTime,
ShipDate DateTime,
CalendarYearMonth string,
INDEX IDX_FactInternetSales_NonPartitioned_CustomerKey CLUSTERED(CustomerKey ASC)
DISTRIBUTED BY HASH(CustomerKey) INTO 25
);
The INTO clause in the above script specifies the number of buckets into which the data will be distributed. The number of distributions must be between 2 and 2500. If INTO is not specified, the data will be distributed across 25 distributions.
Remember, if you have a table with 10 partitions, the table is distributed into 25 distributions buckets. It means total number of distribution buckets are equal to total number of partitions multiplied by defined distribution buckets (10 * 25 = 250 distributions). Keep this formula in mind, as distributions with only a few records can impact performance negatively.
Summary
Similar to other database systems and SQL-inspired Big Data processing systems such as Hive, U-SQL uses the concept of a table to provide a data container that contains schematized structured data. Tables provide additional optimizations beyond a schematized view over unstructured files. Some of these optimizations consists of having the data arranged according to a key, the option to partition the table into several individually addressable partition buckets, the ability to internally partition the table or one of its partition buckets according to a partition key, and finally store the data in their native type serialization formats.
U-SQL tables are backed by files. Each table partition is mapped to its own file, and each INSERT statement adds an additional file (unless a table is rebuilt with ALTER TABLE REBUILD). If the file count of a table (or set of tables) grows beyond a certain limit and the query predicate cannot eliminate files (e.g., due to too many insertions), there is a large likely-hood that the compilation times out after 25 minutes. Currently, if the number of table-backing files exceeds the limit of 3,000 files per job you will receive the following warning:
Warning: WrnExceededMaxTableFileReadThreshold
Message: Script exceeds the maximum number of table or partition files allowed to be read. This message will be upgraded to an error message in next deployment.
Creating a table from a RowSet
If you have a RowSet creating a table from it is very simple. The one thing you must remember is that a table must have an index defined. The table gets its schema from the schema of the rowset.
@customers =
SELECT * FROM
(VALUES
("Contoso", 123 ),
("Woodgrove", 456 )
) AS D( Customer, Id );
DROP TABLE IF EXISTS MyDB.dbo.Customers;
CREATE TABLE MyDB.dbo.Customers
(
INDEX idx
CLUSTERED(customer ASC)
DISTRIBUTED BY HASH(customer)
) AS SELECT * FROM @customers;
Creating an empty table and filling it latter
If you need don’t have the data available at the time of table creation. You can create an empty table as shown below. Notice that this time the schema has to be specified.
DROP TABLE IF EXISTS MyDB.dbo.Customers;
CREATE TABLE MyDB.dbo.Customers
(
Customer string,
Id int,
INDEX idx
CLUSTERED(Customer ASC)
DISTRIBUTED BY HASH(Customer)
);
Then separately, you can fill the table.
@customers =
SELECT * FROM
(VALUES
("Contoso", 123 ),
("Woodgrove", 456 )
) AS D( Customer, Id );
INSERT INTO MyDB.dbo.Customers
SELECT * FROM @customers;
Reading from a table
@rs =
SELECT *
FROM MyDB.dbo.Customers;