In today’s fast-evolving tech landscape, the demand for personalized, contextually aware conversational systems is higher than ever. Whether you’re developing customer support bots, virtual personal assistants, or interactive educational tools, leveraging advanced models like Retrieval-Augmented Generation (RAG) can transform your approach to handling personal data. This article delves deeply into how RAG models, combined with state-of-the-art techniques like embeddings, vector databases, and frameworks such as LangChain, can revolutionize personalized chat experiences.
What is Retrieval-Augmented Generation (RAG)?
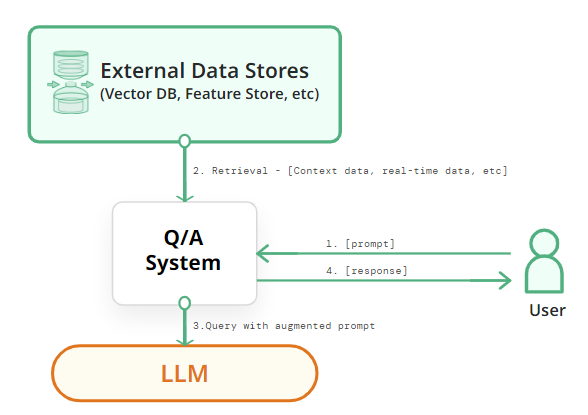
Retrieval-Augmented Generation (RAG) is a sophisticated model architecture that combines retrieval-based methods with generative models to produce more accurate and contextually relevant responses. The primary innovation behind RAG is its dual approach:
- Retrieval Component: This retrieves relevant documents or pieces of information from an external knowledge base based on the input query.
- Generative Component: This leverages the retrieved information to generate coherent and contextually appropriate responses.
Why Use RAG?
RAG models are particularly useful in scenarios where the conversational system needs to handle a vast amount of domain-specific or personalized data. Traditional generative models, while powerful, might struggle with specific or detailed queries unless augmented by additional information retrieval.
Key Concepts Behind RAG
To fully grasp how RAG models work, it’s essential to understand several key concepts:
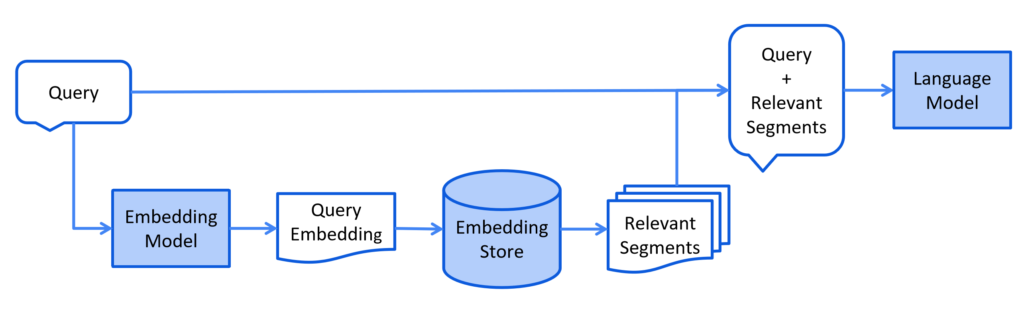
1. Embeddings
Embeddings are numerical representations of text that capture semantic meaning. They transform textual data into high-dimensional vectors, making it easier for models to process and understand.
- Word Embeddings: Represent individual words as vectors. Examples include Word2Vec and GloVe.
- Sentence Embeddings: Capture the meaning of entire sentences or phrases. Examples include BERT embeddings and Sentence-BERT.
2. Vector Databases
Vector databases are designed to store and efficiently search high-dimensional vectors. These databases are crucial for the retrieval component of a RAG model, enabling quick and accurate similarity searches.
- Pinecone: A managed vector database that supports real-time search and retrieval.
- FAISS: An open-source library developed by Facebook for efficient similarity search and clustering of dense vectors.
3. LangChain
LangChain is a powerful framework that simplifies the integration of large language models with external data sources. It provides tools to chain together various components of a conversational system, including retrieval and generation, streamlining the development process.
4. Pretrained Models
Pretrained models like GPT-4, BERT, and T5 are foundational to many modern NLP applications. These models are trained on large corpora and can be fine-tuned for specific tasks. In the context of RAG, they serve as the generative component that creates responses based on retrieved information.
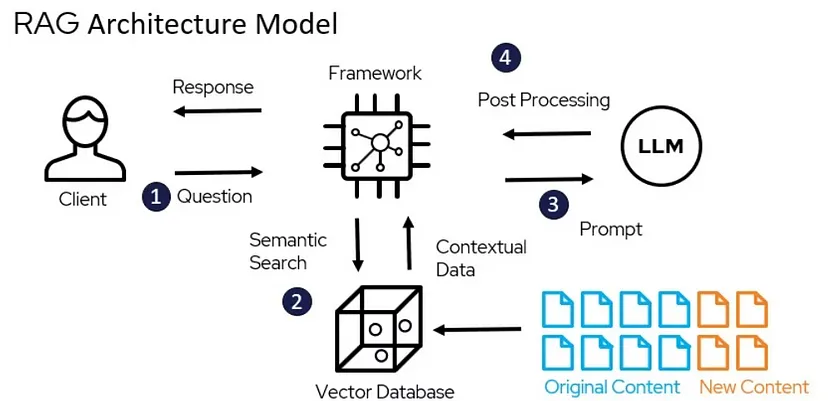
The Architecture of a RAG Model
Understanding the architecture of a RAG model involves breaking down its core components and their interactions:
- Query Encoding: The user’s input query is first converted into a vector representation using an embedding model. This step captures the semantic content of the query.
- Document Retrieval: The query vector is used to search a vector database for relevant documents. The database returns documents that are most similar to the query vector.
- Contextual Response Generation: The retrieved documents are combined with the original query and passed to the generative model. The generative model uses this information to produce a response that is contextually relevant.
- Response Output: The generated response is then delivered to the user.
Implementing RAG for Personalized Chat
Implementing a RAG-based conversational system involves several key steps:
Step 1: Prepare Your Data
Start by gathering and preparing your personal data. This may include user preferences, interaction history, or other relevant information. Ensure that your data is clean, structured, and ready for processing.
Step 2: Create Embeddings
Use an embedding model to convert your textual data into high-dimensional vectors. Tools like Sentence-BERT are effective for creating sentence embeddings that capture semantic meaning.
Step 3: Set Up the Vector Database
Choose a vector database that fits your needs. Pinecone and FAISS are popular choices. Load your embeddings into the database and ensure that it’s properly indexed for efficient retrieval.
Step 4: Integrate with LangChain
LangChain facilitates the integration of your retrieval and generative components. Set up LangChain to handle query processing, retrieve relevant documents from your vector database, and interact with your generative model.
Step 5: Fine-Tune the Generative Model
Fine-tune your generative model (e.g., GPT-4) on domain-specific data to improve its performance. Fine-tuning helps the model generate more relevant and accurate responses based on your specific use case.
Step 6: Deploy and Test
Deploy your RAG-based system and conduct extensive testing with real users. Monitor its performance and make adjustments as needed to enhance response quality and relevance.
Real-World Applications
1. Customer Support
In customer support, RAG models can enhance response accuracy by retrieving relevant product or service information. This leads to more precise answers and a better overall customer experience.
2. Virtual Assistants
For virtual assistants, RAG models can personalize interactions based on user preferences and past interactions. This creates a more engaging and relevant user experience.
3. Educational Tools
In educational applications, RAG models can provide tailored explanations and resources based on the student’s progress and needs, facilitating more effective learning.
Challenges and Considerations
While RAG models offer significant advantages, there are some challenges to be aware of:
- Data Privacy: Ensure that personal data is handled securely and in compliance with relevant regulations.
- Model Complexity: Integrating multiple components (retrieval, embeddings, generation) can add complexity to the system.
- Performance: Real-time retrieval and generation require efficient algorithms and infrastructure.
Conclusion
Retrieval-Augmented Generation (RAG) models offer a powerful approach to creating personalized conversational systems. By combining retrieval-based techniques with generative models, you can build systems that deliver more accurate and contextually relevant interactions. With the integration of embeddings, vector databases, and frameworks like LangChain, you have the tools to harness the full potential of your data and create exceptional AI-driven experiences.
As you embark on building your RAG-based applications, remember to continuously evaluate and refine your system to meet user needs effectively. The future of personalized AI is here, and with RAG, you’re well-equipped to be at the forefront of this exciting field.
For further exploration and resources on RAG models and personalized AI, stay tuned to our blog and join the conversation on the latest advancements in AI technology. Happy building!