
What is Apache Kafka?
Kafka is a Publish-Subscribe based messaging system that is exchanging data between processes, applications, and servers. Applications may connect to this system and transfer a message onto the Topic(we will see in a moment what topic is) and another application may connect to the system and process messages from the Topic.
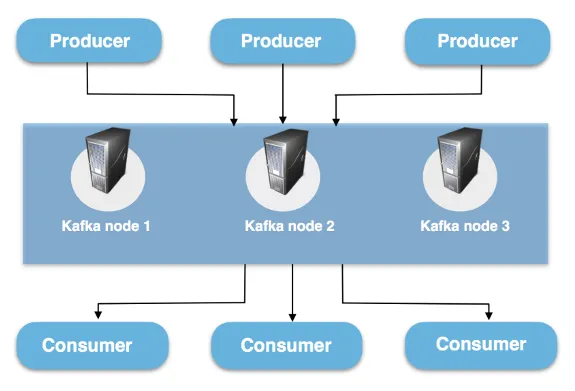
What is Kafka Broker?
Kafka cluster consist of one or more servers also known as Kafka brokers, which are running Kafka. Each broker is identified with its ID(Broker.id property is the unique and permanent name of each node in the cluster).To connect to the entire cluster, you first need to connect to bootstrap server(also called bootstrap broker).Bootstrap Servers are nothing but list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
What is Kafka Topic?
A Topic is a category/feed name to which messages are stored and published.
- Messages are byte arrays that can store any object in any format.
- All Kafka messages are organized into topics.
- If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic.
- Producer applications write data to topics and consumer applications read from topics.
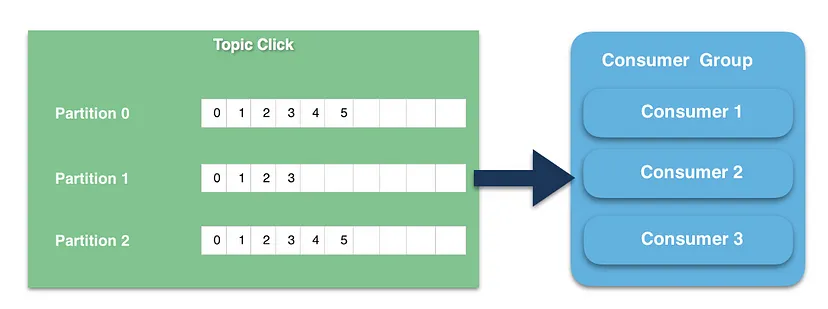
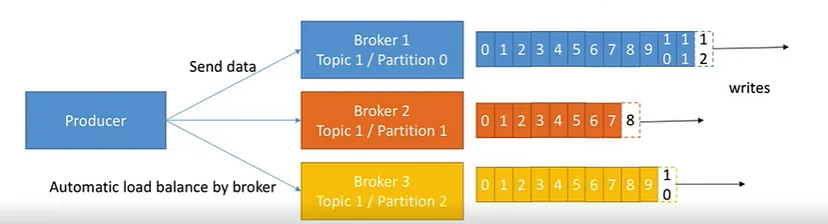
How does Kafka Topic Partition Look?
- Kafka topics are divided into a number of partitions, which contain messages in an unchangeable sequence.
- Each message in a partition is assigned and identified by its unique offset.
- A topic partition is a unit of parallelism in Kafka, i.e. two consumers cannot consume messages from the same partition at the same time. A consumer can consume from multiple partitions at the same time.
Replica In Kafka
- In Kafka, replication is implemented at the partition level.
- The redundant unit of a topic partition is called a replica.
- Each partition usually has one or more replicas meaning that partitions contain messages that are replicated over a few Kafka brokers in the cluster.
Example of 2 topics(3 partitions and 2 partitions)
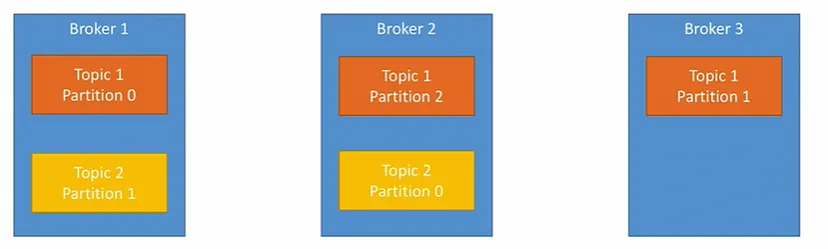
Data is distributed and broker 3 doesn’t have any topic 2 data
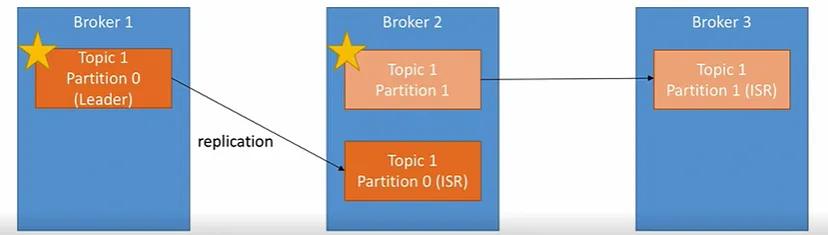
Concept of Leader for a Partition
- At any time only a single broker can be a leader for a given partition and only that leader can receive and serve data for a partition
- The other brokers will synchronize the data
- There each partition has only one leader and multiple ISR(In-Sync-Replica)
Consumers
- Consumers can join a group called a consumer group.
- Each consumer in the group is assigned a set of partitions to consume from.
- Kafka guarantees that a message is only read by a single consumer in the group
- Data/messages are never pushed out to consumers, the consumer will ask for messages when the consumer is ready to handle the message.
- The consumers will never overload themselves with lots of data or lose any data since all messages are being queued up in Kafka.
- Consumers read data in consumer groups
- Each consumer within a group reads from exclusive partitions
- You cannot have more consumers than partitions(otherwise some will be inactive)

Producers
- Producers can choose to receive acknowledgment of data writes:
- Acks=0: Producer won’t wait for an acknowledgment (possible data loss)
- Acks=1: Producer will wait for leader acknowledgment (limited data loss)
- Acks=all: Leader + replicas acknowledgment(no data loss)
Here are important concepts that you need to remember
- Producer: Application that sends the messages.
- Consumer: Application that receives the messages.
- Message: Information that is sent from the producer to a consumer through Apache Kafka.
- Connection: A connection is a TCP connection between your application and the Kafka broker.
- Topic: A Topic is a category/feed name to which messages are stored and published.
- Topic partition: Kafka topics are divided into a number of partitions, which allows you to split data across multiple brokers.
- Replicas A replica of a partition is a “backup” of a partition. Replicas never read or write data. They are used to prevent data loss.
- Consumer Group: A consumer group includes the set of consumer processes that are subscribing to a specific topic.
- Offset: The offset is a unique identifier of a record within a partition. It denotes the position of the consumer in the partition.
- Node: A node is a single computer in the Apache Kafka cluster.
- Cluster: A cluster is a group of nodes i.e., a group of computers.
- Note: Zookeeper manages brokers(keep a list of them). It helps in performing leader election for partitions. It also sends a notification to Kafka in case of changes. Kafka can not work without zookeeper.
References