TAKING AN END-TO-END LOOK FROM INGEST TO REPORTING!
Introduction
There are a lot of scenario’s where organization are leveraging Azure to process their data at scale. In today’s post I’m going to go through the various pieces that can connect the puzzle for you in such a work flow. Starting from ingesting the data into Azure, and afterwards processing it in a scalable & sustainable manner.
High Level Architecture
As always, let’s start with a high level architecture to discuss what we’ll be discussing today ;
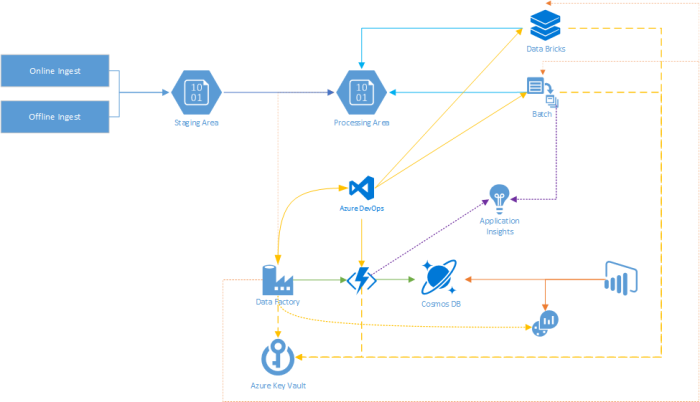
- Ingest : The entire story starts here, where the data is being ingested into Azure. This can be done via an offline transfer (Azure DataBox), or online via (Azure DataBox Edge/Gateway, or using the REST API, AzCopy, …).
- Staging Area : No matter what ingestation method you’re using, the data will end up in a storage location (which we’ll now dub “Staging Area”). From there one we’ll be able to transfer it to it’s “final destination”.
- Processing Area : This is the “final destination” for the ingested content. Why does this differ from the staging area? Cause there are a variety of reasons to put data in another location. Ranging from business rules and the linked conventions (like naming, folder structure, etc), towards more technical reasons like proximity to other systems or spreading the data across different storage accounts/locations.
- Azure Data Factory : This service provides a low/no-code way of modelling out your data workflow & having an awesome way of following up your jobs in operations. It’ll serve as the key orchestrator for all your workflows.
- Azure Functions : Where there are already a good set of activities (“tasks”) available in ADF (Azure Data Factory), the ability to link functions into it extends the possibility for your organization even more. Now you can link your custom business logic right into the workflows.
- Cosmos DB : As you probably want to keep some metadata on your data, we’ll be using Cosmos DB for that one. Where Functions will serve as the front-end API layer to connect to that data.
- Azure Batch & Data Bricks : Both Batch & Data Bricks can be directly called upon from ADF, providing key processing power in your workflows!
- Azure Key Vault : Having secrets lying around & possibly being exposed is never a good idea. Therefor it’s highly recommended to leverage the Key Vault integration for storing your secrets!
- Azure DevOps : Next to the above, we’ll be relying on Azure DevOps as our core CI/CD pipeline and trusted code repository. We can use it to build & deploy our Azure Functions & Batch Applications, as for storing our ADF templates & Data Bricks notebooks.
- Application Insights : Key to any successful application is collecting the much needed telemetry, where Application Insights is more than suited for this task.
- Log Analytics : ADF provides native integration with Log Analytics. This will provide us with an awesome way to take a look at the status of our pipelines & activities.
- PowerBI : In terms of reporting, we’ll be using PowerBI to collect the data that was pumped into Log Analytics and joining it with the metadata from Cosmos DB. Thus providing us with live data on the status of our workflow!
Read more at https://tinyurl.com/yapmlynq