In today’s data-driven world, the ability to efficiently collect, process, and analyze large volumes of data is paramount. This blog post will delve into a data engineering project that leverages a powerful combination of tools: Python, Docker, Airflow, Spark, Kafka, and Cassandra.
We’ll explore how these technologies work together to create a robust and scalable data pipeline, capable of handling real-time data ingestion, transformation, and storage. From setting up the environment with Docker to designing and implementing data workflows using Airflow, we’ll cover the key steps and considerations involved in this project.
This pipeline retrieves random user data from an API, processes it in real-time, and stores it for further analysis. We’ll also use Docker to containerize the entire setup for seamless deployment.
Project Overview
Our project implements a data pipeline that performs the following tasks:
- Data Retrieval: Fetch random user data from an API.
- Data Streaming: Stream this data to Kafka topics.
- Real-Time Processing: Process the data using Spark Structured Streaming.
- Data Storage: Store the processed data in Cassandra.
System Architecture
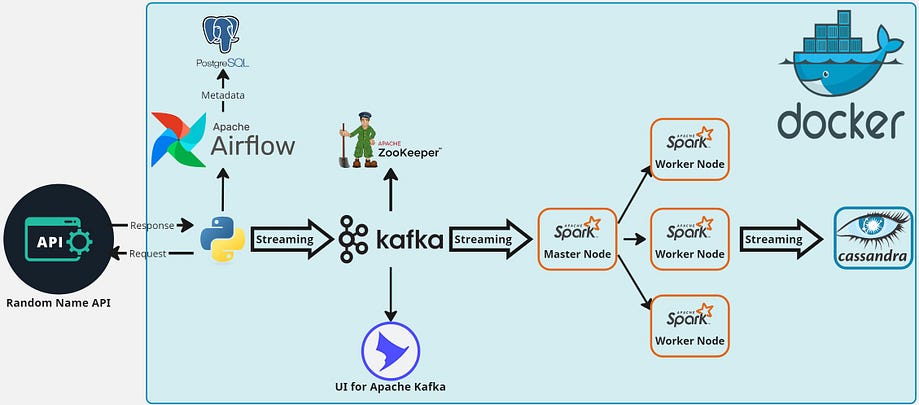
The system consists of several key components:
- Data Source: The
randomuser.meAPI provides user data. - Apache Airflow: Orchestrates the pipeline and schedules data ingestion.
- Apache Kafka & Zookeeper: Handles the real-time data streaming.
- Apache Spark: Processes data in real-time.
- Cassandra: Stores the processed data.
- Docker: Containerizes the entire setup for consistency and ease of deployment.
Getting Started
Prerequisites
Ensure you have Docker installed on your machine. Docker Compose will be used to spin up all necessary services.
Clone the Repository
First, clone the repository containing the project code:
git clone https://github.com/akarce/e2e-structured-streaming.git
cd e2e-structured-streamingConfigure Environment
Create an .env file and set the Airflow UID and make the entrypoint script executable:
echo -e "AIRFLOW_UID=$(id -u)" > .env
echo AIRFLOW_UID=50000 >> .env
chmod +x script/entrypoint.shThis project consists of 2 folders and 6 files organized as follows:
├── dags
│ └── kafka_stream.py
├── docker-compose.yaml
├── requirements.txt
├── dependencies.zip
├── script
│ └── entrypoint.sh
└── spark_stream.py
2 directories, 6 filesThe entrypoint.sh file contains the commands to be executed after the container is initialized. To ensure it functions correctly, it is recommended to run chmod +x scripts/entrypoint.sh from the root directory to make the script executable.
#!/bin/bash
set -e
if [ -e "/opt/airflow/requirements.txt" ]; then
python -m pip install --upgrade pip
pip install -r requirements.txt
fi
if [ ! -f "/opt/airflow/airflow.db" ]; then
airflow db migrate && \
airflow users create \
--username admin \
--firstname admin \
--lastname admin \
--role Admin \
--email admin@example.com \
--password admin
fi
$(command -v airflow) db upgrade
exec airflow webserverBelow is the content of the dockerfile.yaml used to orchestrate the setup process.
Note: The AIRFLOW__WEBSERVER__SECRET_KEY must be consistent between the webserver and the scheduler for the containers to function correctly.
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.9.3}
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN : postgresql+psycopg2://airflow:airflow@postgres:5432/airflow
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'false'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: 'true'
_PIP_ADDITIONAL_REQUIREMENTS: "kafka-python-ng==2.2.2 ${_PIP_ADDITIONAL_REQUIREMENTS:-}"
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/script/entrypoint.sh:/opt/airflow/script/entrypoint.sh
- ${AIRFLOW_PROJ_DIR:-.}/requirements.txt:/opt/airflow/requirements.txt
user: "${AIRFLOW_UID:-50000}:0"
depends_on:
&airflow-common-depends-on
postgres:
condition: service_healthy
services:
postgres:
image: postgres:13
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 10s
retries: 5
start_period: 5s
restart: always
networks:
- streamsnet
airflow-webserver:
<<: *airflow-common
build: .
command: webserver
entrypoint: ['/opt/airflow/script/entrypoint.sh']
ports:
- "8080:8080"
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
networks:
- streamsnet
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8974/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
networks:
- streamsnet
airflow-triggerer:
<<: *airflow-common
command: triggerer
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type TriggererJob --hostname "$${HOSTNAME}"']
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
networks:
- streamsnet
airflow-init:
<<: *airflow-common
entrypoint: /bin/bash
command:
- -c
- |
if [[ -z "${AIRFLOW_UID}" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: AIRFLOW_UID not set!\e[0m"
echo "If you are on Linux, you SHOULD follow the instructions below to set "
echo "AIRFLOW_UID environment variable, otherwise files will be owned by root."
echo "For other operating systems you can get rid of the warning with manually created .env file:"
echo " See: https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#setting-the-right-airflow-user"
echo
fi
one_meg=1048576
mem_available=$$(($$(getconf _PHYS_PAGES) * $$(getconf PAGE_SIZE) / one_meg))
cpus_available=$$(grep -cE 'cpu[0-9]+' /proc/stat)
disk_available=$$(df / | tail -1 | awk '{print $$4}')
warning_resources="false"
if (( mem_available < 4000 )) ; then
echo
echo -e "\033[1;33mWARNING!!!: Not enough memory available for Docker.\e[0m"
echo "At least 4GB of memory required. You have $$(numfmt --to iec $$((mem_available * one_meg)))"
echo
warning_resources="true"
fi
if (( cpus_available < 2 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough CPUS available for Docker.\e[0m"
echo "At least 2 CPUs recommended. You have $${cpus_available}"
echo
warning_resources="true"
fi
if (( disk_available < one_meg * 10 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough Disk space available for Docker.\e[0m"
echo "At least 10 GBs recommended. You have $$(numfmt --to iec $$((disk_available * 1024 )))"
echo
warning_resources="true"
fi
if [[ $${warning_resources} == "true" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: You have not enough resources to run Airflow (see above)!\e[0m"
echo "Please follow the instructions to increase amount of resources available:"
echo " https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#before-you-begin"
echo
fi
mkdir -p /sources/logs /sources/dags /sources/plugins
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins}
exec /entrypoint airflow version
environment:
<<: *airflow-common-env
_AIRFLOW_DB_MIGRATE: 'true'
_AIRFLOW_WWW_USER_CREATE: 'true'
_AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow}
_PIP_ADDITIONAL_REQUIREMENTS: ''
user: "0:0"
volumes:
- ${AIRFLOW_PROJ_DIR:-.}:/sources
networks:
- streamsnet
airflow-cli:
<<: *airflow-common
profiles:
- debug
environment:
<<: *airflow-common-env
CONNECTION_CHECK_MAX_COUNT: "0"
command:
- bash
- -c
- airflow
networks:
- streamsnet
kafka:
image: bitnami/kafka:3.7.1
hostname: broker
container_name: broker
depends_on:
zookeeper:
condition: service_healthy
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "9092"]
interval: 10s
retries: 10
start_period: 10s
networks:
- streamsnet
zookeeper:
image: bitnami/zookeeper:3.8.4
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ALLOW_ANONYMOUS_LOGIN : yes
healthcheck:
test: ['CMD', 'bash', '-c', "echo 'ruok' | nc localhost 2181"]
interval: 10s
timeout: 5s
retries: 5
networks:
- streamsnet
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
ports:
- "8085:8080"
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
depends_on:
- kafka
networks:
- streamsnet
spark-master:
image: bitnami/spark:3.5.1
container_name: spark-master
command: bin/spark-class org.apache.spark.deploy.master.Master
ports:
- "9090:8080"
- "7077:7077"
networks:
- streamsnet
spark-worker:
image: bitnami/spark:3.5.1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 1g
SPARK_MASTER_URL: spark://spark-master:7077
networks:
- streamsnet
cassandra_db:
image: cassandra:4.0.13
container_name: cassandra
ports:
- "9042:9042"
environment:
- MAX_HEAP_SIZE=512M
- HEAP_NEWSIZE=100M
- CASSANDRA_USERNAME=cassandra
- CASSANDRA_PASSWORD=cassandra
networks:
- streamsnet
networks:
streamsnet:
driver: bridge
volumes:
postgres-db-volume:Initialize Airflow
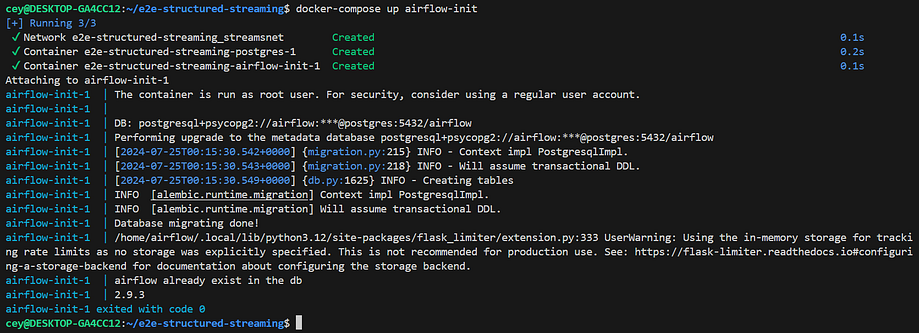
Run Docker Compose to perform database migrations and create the first user account and spin up all services using Docker Compose:
docker-compose up airflow-init
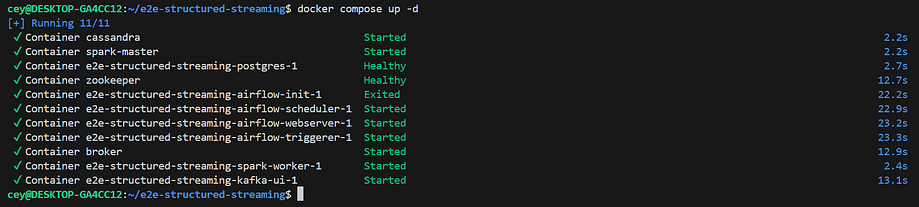
docker compose up -d
Once the Docker containers are up and running, create a new file in the dags directory named stream_kafka.py. Here is the content of the file:
from datetime import datetime
from airflow import DAG
from airflow.operators.python import PythonOperator
import random
default_args = {
'owner': 'admin',
'start_date': datetime(2023, 9, 3, 10, 00)
}
def get_data():
import requests
res = requests.get("https://randomuser.me/api/")
res = res.json()
res = res['results'][0]
return res
def format_data(res):
data = {}
location = res['location']
data['first_name'] = res['name']['first']
data['last_name'] = res['name']['last']
data['gender'] = res['gender']
data['address'] = f"{str(location['street']['number'])} {location['street']['name']}, " \
f"{location['city']}, {location['state']}, {location['country']}"
data['post_code'] = location['postcode']
data['email'] = res['email']
data['username'] = res['login']['username']
data['dob'] = res['dob']['date']
data['registered_date'] = res['registered']['date']
data['phone'] = res['phone']
data['picture'] = res['picture']['medium']
return data
def stream_data():
import json
from kafka import KafkaProducer
import time
import logging
producer = KafkaProducer(bootstrap_servers='broker:9092', max_block_ms=5000)
curr_time = time.time()
while True:
if time.time() > curr_time + 120: #2 minutes
break
try:
res = get_data()
res = format_data(res)
producer.send('users_created', json.dumps(res).encode('utf-8'))
sleep_duration = random.uniform(0.5, 2.0)
time.sleep(sleep_duration)
except Exception as e:
logging.error(f'An error occured: {e}')
continue
with DAG('user_automation',
default_args=default_args,
schedule_interval='@daily',
catchup=False) as dag:
streaming_task = PythonOperator(
task_id='stream_data_from_api',
python_callable=stream_data
)Go to the Airflow UI at http://localhost:8080, and unpause the user_automation DAG by clicking the switch button in the DAG section.

To view the data streams on Kafka, you can visit http://localhost:8085 in your browser.
In the root directory of the project there is a file called spark_stream.py to read kafka topic named users_created.
import logging
from datetime import datetime
from cassandra.cluster import Cluster
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json
from pyspark.sql.types import StructType, StructField, StringType
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)
def create_keyspace(session):
session.execute("""
CREATE KEYSPACE IF NOT EXISTS spark_streaming
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1}
""")
logger.info("Keyspace created successfully")
def create_table(session):
session.execute("""
CREATE TABLE IF NOT EXISTS spark_streaming.created_users (
first_name TEXT,
last_name TEXT,
gender TEXT,
address TEXT,
post_code TEXT,
email TEXT,
username TEXT PRIMARY KEY,
dob TEXT,
registered_date TEXT,
phone TEXT,
picture TEXT);
""")
logger.info("Table created successfully")
def insert_data(session, **kwargs):
logger.info("Inserting data")
first_name = kwargs.get('first_name')
last_name = kwargs.get('last_name')
gender = kwargs.get('gender')
address = kwargs.get('address')
postcode = kwargs.get('post_code')
email = kwargs.get('email')
username = kwargs.get('username')
dob = kwargs.get('dob')
registered_date = kwargs.get('registered_date')
phone = kwargs.get('phone')
picture = kwargs.get('picture')
try:
session.execute("""
INSERT INTO spark_streaming.created_users (first_name, last_name, gender, address,
post_code, email, username, dob, registered_date, phone, picture)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (first_name, last_name, gender, address,
postcode, email, username, dob, registered_date, phone, picture))
logger.info(f"Data inserted for {first_name} {last_name}")
except Exception as e:
logger.error(f"Error while inserting data: {e}")
def create_spark_connection():
s_conn = None
try:
s_conn = SparkSession.builder \
.appName('SparkDataStreaming') \
.config('spark.jars.packages', "com.datastax.spark:spark-cassandra-connector_2.12:3.5.1,"
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1") \
.config('spark.cassandra.connection.host', 'cassandra_db') \
.getOrCreate()
s_conn.sparkContext.setLogLevel("ERROR")
logger.info("Spark connection created successfully")
except Exception as e:
logger.error(f"Error while creating spark connection: {e}")
return s_conn
def connect_to_kafka(spark_conn):
spark_df = None
try:
spark_df = spark_conn.readStream \
.format('kafka') \
.option('kafka.bootstrap.servers', 'broker:9092') \
.option('subscribe', 'users_created') \
.option('startingOffsets', 'earliest') \
.load()
logger.info("Kafka dataframe created successfully")
except Exception as e:
logger.error(f"Kafka dataframe could not be created because: {e}")
logger.error(f"Error type: {type(e).__name__}")
logger.error(f"Error details: {str(e)}")
import traceback
logger.error(f"Traceback: {traceback.format_exc()}")
if spark_df is None:
logger.error("Failed to create Kafka dataframe")
return spark_df
def create_cassandra_connection():
try:
# Connection to Cassandra cluster
cluster = Cluster(['cassandra_db'])
cas_session = cluster.connect()
logger.info("Cassandra connection created successfully")
return cas_session
except Exception as e:
logger.error(f"Error while creating Cassandra connection: {e}")
return None
def create_selection_df_from_kafka(spark_df):
schema = StructType([
StructField("first_name", StringType(), False),
StructField("last_name", StringType(), False),
StructField("gender", StringType(), False),
StructField("address", StringType(), False),
StructField("post_code", StringType(), False),
StructField("email", StringType(), False),
StructField("username", StringType(), False),
StructField("dob", StringType(), False),
StructField("registered_date", StringType(), False),
StructField("phone", StringType(), False),
StructField("picture", StringType(), False)
])
sel = spark_df.selectExpr("CAST(value AS STRING)") \
.select(from_json(col("value"), schema).alias("data")) \
.select("data.*")
logger.info("Selection dataframe created successfully")
return sel
if __name__ == "__main__":
# Create Spark connection
spark_conn = create_spark_connection()
if spark_conn is not None:
# Create connection to Kafka with Spark
spark_df = connect_to_kafka(spark_conn)
selection_df = create_selection_df_from_kafka(spark_df)
logger.info("Selection dataframe schema:")
selection_df.printSchema()
# Create Cassandra connection
session = create_cassandra_connection()
if session is not None:
create_keyspace(session)
create_table(session)
# Insert data into Cassandra
insert_data(session)
streaming_query = selection_df.writeStream.format("org.apache.spark.sql.cassandra") \
.option('keyspace', 'spark_streaming', ) \
.option('checkpointLocation', '/tmp/checkpoint') \
.option('table', 'created_users') \
.start()
streaming_query.awaitTermination()
session.shutdown()Prepare Spark and Cassandra
Copy the dependencies and spark_stream files into the Spark container:
docker cp dependencies.zip spark-master:/dependencies.zip
docker cp spark_stream.py spark-master:/spark_stream.py

Access the Cassandra container and verify that there is no keyspace named created_users:
docker exec -it cassandra cqlsh -u cassandra -p cassandra localhost 9042
cqlsh> DESCRIBE KEYSPACES;

Run the Spark job to start processing data:
docker exec -it spark-master spark-submit \
--packages com.datastax.spark:spark-cassandra-connector_2.12:3.5.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 \
--py-files /dependencies.zip \
/spark_stream.pyMonitor the Pipeline
Access Airflow UI at http://localhost:8080/ and unpause the user_automation DAG.
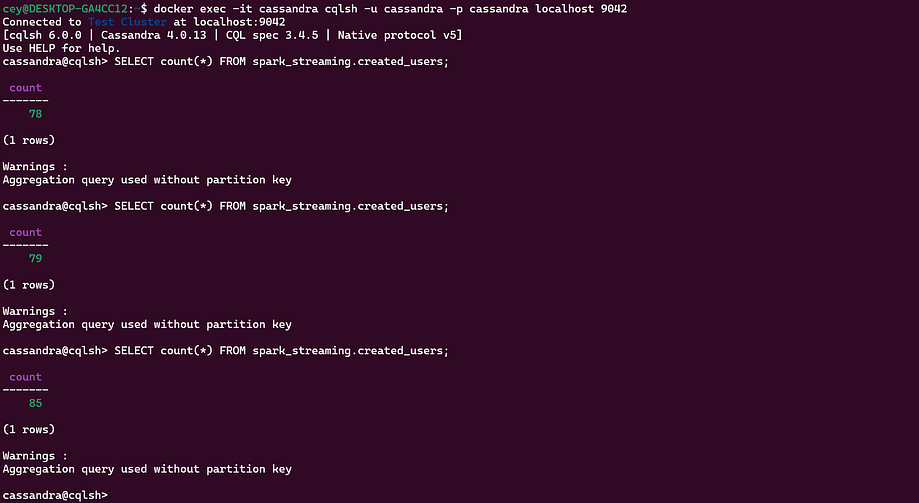
Check Cassandra to verify that data is being inserted:
docker exec -it cassandra cqlsh -u cassandra -p cassandra localhost 9042
cqlsh> SELECT * FROM spark_streaming.created_users;
cqlsh> SELECT count(*) FROM spark_streaming.created_users;
By effectively utilizing Python, Docker, Airflow, Spark, Kafka, and Cassandra, we’ve successfully constructed a scalable and efficient data pipeline. This project demonstrates the power of modern data tools in handling large-scale data processing and analysis.
The ability to ingest, process, and store data in real-time has become increasingly essential for businesses seeking to gain valuable insights and make data-driven decisions. The techniques and technologies explored in this blog post provide a solid foundation for building robust and scalable data engineering solutions.